
We’re excited to introduce support for Stable Diffusion XL 1.0 in Magai, giving you access to the latest advances in AI image generation.
Stable Diffusion XL significantly improves upon previous versions with higher resolution, more realistic and precise image synthesis capabilities. With Magai, you now have a simple yet powerful tool to explore this next-generation AI image generation model.
In this article, we’ll cover the major upgrades and new features that set Stable Diffusion XL apart. We’ll demonstrate how you can access SDXL through Magai’s intuitive interface and provide recommended techniques to help you generate stunning imagery. Stable Diffusion XL represents a big step forward in AI-powered visual creativity, and we’re thrilled to bring this capability to Magai users.
Table of Contents:
- What’s New In Stable Diffusion XL 1.0
- Higher Resolution
- The XL Archetecture
- Ensemble of Experts Architecture
- Commercial License + Open Source
- Image Quality & Capabilities
- Ethical Concerns & Mitigation
- Using Stable Diffusion XL
- Looking Ahead
In line with Stability AI’s open source release, we decided to integrate Stable Diffusion XL 1.0 into Magai to provide our users with the most cutting-edge AI image synthesis model available. We hope SDXL will inspire new forms of creative expression and help bring your visions to life.
What’s New in Stable Diffusion XL 1.0
Stable Diffusion XL 1.0 represents a major upgrade over previous versions of Stable Diffusion, offering several new capabilities and improvements that take AI image generation to the next level.
Let’s cover all the new things that Stable Diffusion XL (SDXL) brings to the table.
Higher resolution up to 1024×1024

Stable Diffusion XL can produce images at a resolution of up to 1024×1024 pixels, compared to 512×512 for SD 1.5 and 768×768 for SD 2.0. The higher resolution enables far greater detail and clarity in generated imagery.
The jump from 768×768 in SD 2.0 to 1024×1024 in SDXL represents a significant increase in the number of pixels – nearly 4 times as many. This allows SDXL to resolve finer details like textures, patterns and facial features with much higher fidelity. Images can have sharper edges, smoother gradients and more natural color transitions at the 1024×1024 resolution.
The higher resolution also enables SDXL to generate image elements that were difficult for previous models, like logos and other forms of textual information, as well as complex objects with intricate parts. The enlarged model size and ensemble of experts architecture give SDXL the capability to discern and reproduce finer aspects of visual scenes at the 1024×1024 pixel level.
Overall, the addition of more pixels and visual information allows Stable Diffusion XL to produce imagery with a new level of hyperrealism and photo-accuracy, especially for scenes with lots of visual details and complications.
Better photorealism and image detail

Stable Diffusion XL produces imagery with more accurate colors, better contrast and shadows, and higher definition features. This results in images that appear more realistic and photo-like. According to Stability AI, data shows people prefer images generated by SDXL for their photorealism and image quality.
Compared to previous versions of Stable Diffusion, SDXL’s improved neural network architecture and training data enable photorealistic visual synthesis with unprecedented quality and precision. Example images show sharply defined details, correct lighting and shadows, and realistic compositions.
Support for inpainting, outpainting and image-to-image generation
Stable Diffusion XL can modify existing images in various ways beyond just generating images from text prompts. It supports inpainting to reconstruct missing parts of an image, outpainting to extend an existing image, and image-to-image generation where an input image acts as a prompt.
Inpainting, outpainting and image-to-image generation give artists more flexibility and control over the visual synthesis process. They allow artists to:
- Remove unwanted objects from photos and fill in the blanks in a coherent manner
- Extend the boundaries of an image naturally, continuing patterns and textures
- Modify an existing image by modifying the prompt while keeping the general composition
These techniques enable novel applications of AI art generation like restoring damaged historical photographs, expanding limited canvas sizes, altering product shots for different colorways, and modifying portraits with tweaks to facial expressions or hair styles.
Overall, the ability to modify and transform existing images in addition to generating novel scenes from scratch gives Stable Diffusion XL an extra dimension of visual creative capability beyond just text-to-image generation.
Enhanced text generation and legibility

According to Stability AI, Stable Diffusion XL can handle simpler language in prompts better, requiring fewer complex qualifiers to generate high-quality images. It also shows improved capabilities for producing legible text within images.
Understanding language at a more intuitive level allows SDXL to align text prompts more closely with the intended visual output. This gives artists more natural control over the image generation process.
For legibility, SDXL’s two separate text encoders – which parse prompts into a latent space – enable finer control over textual elements within images. This allows SDXL to reproduce readable logos, signs, labels and other text-based details with higher accuracy.
Example images generated by SDXL demonstrate its ability to produce legible text overlaid on images, embedded within scenes and on objects like signs, apparel and billboards. Compared to previous versions of Stable Diffusion, the text elements exhibit sharper character definitions and fewer distortions.
Overall, SDXL’s enhanced handling of language and text points to an advance in its ability to parse and reproduce the semantic and syntactic components of visual realism – an important step toward more generally intelligent image generation.
Faster model training capability

According to Stability AI, Stable Diffusion XL requires less data wrangling to fine-tune into custom models and LAIONs, resulting in faster training times and better performance from fewer training iterations.
The increased speed and efficiency of training SDXL stems from its larger size and more sophisticated architecture. With 3.5 billion parameters, SDXL contains significantly more representational capacity than previous Stable Diffusion models. This allows it to generalize better from limited training data, reducing the data volume needed to fine-tune the model for specific use cases.
As a result, researchers, artists and hobbyists can potentially realize their own custom versions of SDXL – specialized for narrower purposes like specific art styles, subject matter or aesthetics – in less time and with fewer computational resources.
Overall, SDXL’s faster finetunability promises to accelerate and expand the creative applications of latent diffusion models by lowering the bar for custom model development. We may see a profusion of niche and specialized SDXL variants emerge from the AI art community that push the boundaries of visual creativity.
The XL Architecture

The enhancements and new capabilities of Stable Diffusion XL stem from upgrades to its underlying architecture. Beyond just being a larger model with more parameters, SDXL utilizes several novel techniques that enable its image generation improvements. Understanding these architectural innovations provides insight into how SDXL works its “magic” – and how it may continue to progress in the future.
Larger UNet backbone with 3.5 billion parameters
Stable Diffusion XL contains a “three times larger UNet backbone” compared to previous versions, according to Stability AI. This enlarged neural network architecture, totaling 3.5 billion parameters, gives SDXL more representational power to generate higher resolution, more detailed images.
UNet refers to an encoder-decoder style convolutional neural network commonly used for image-to-image translation tasks. The UNet backbone is the core part of the Stable Diffusion model that processes text prompts and image data.
By expanding the UNet backbone from 1.3 billion parameters in SD 1.5 to 3.5 billion in SDXL, Stability AI gave the model significantly more “room to think” – enabling it to discern and reproduce finer levels of visual detail at the 1024×1024 pixel scale. The addition of over 2 billion extra parameters likely contributed greatly to SDXL’s improvements in photorealism, text legibility and other capabilities.
In essence, the enlarged UNet backbone provided SDXL with a more sophisticated “vision system” – allowing it to perceive and reconstruct complex scenes with an unprecedented degree of photographic verisimilitude.
Ensemble of experts architecture
According to Stability AI, Stable Diffusion XL uses a novel “ensemble of experts” approach that guides the latent diffusion process. This refers to a methodology where an initial base model is split into specialized sub-models specifically trained for different stages of the generation process.
In SDXL’s case, there is a base model that performs the initial text-to-image generation, and an optional “refiner” model that can further modify the base image to improve quality. Used together, these two models form an “ensemble of experts” that divide and conquer the image synthesis task.
The ensemble of experts approach likely contributes to SDXL’s enhanced performance in several ways:
1) The refiner model can correct artifacts and inconsistencies missed by the base model, producing higher fidelity outputs.
2) The separate models can specialize on different aspects of the image – like color, composition or text – optimizing each one independently.
3) Combining the outputs of multiple large models tends to produce more robust and reliable results than a single monolithic model.
Overall, the ensemble of experts architecture gives SDXL a degree of “peer review” during image generation, allowing it to catch and correct its own mistakes – much like how human experts collaborate to improve their work. This helps explain SDXL’s advances in photorealism, legibility and consistency compared to previous SD versions.
Two text encoders
According to Stability AI, Stable Diffusion XL uses two different text encoders that make sense of the written prompt. This allows users to provide a different prompt to each encoder, resulting in novel, high-quality concept combinations within a single generated image.
By incorporating two separate text encoders, SDXL gains a degree of “binocular vision” when parsing prompts – allowing it to perceive two different concepts within the same visual scene. This enables users to combine unrelated ideas within a single prompt, often with seamless, sophisticated results.
For example, as demonstrated by AI researcher Xander Steenbrugge, combining the prompts “an Indian elephant” and “an octopus” – fed into separate text encoders – results in a coherent image of an elephant with octopus-like tentacles. Both subjects are realistically integrated into a single visual concept.
The two text encoders likely contribute to SDXL’s enhanced capability for generating complex compositions with multiple subjects, detailed backgrounds and other sophisticated visual scenarios. By parsing a scene into multiple conceptual components, SDXL can model the spatial and semantic relationships between elements more naturally.
The addition of a second text encoder represents an important evolution in the architecture of generative AI models. It points to a future where more “polymath” models incorporating multiple specialized subnetworks may emerge.
Commercial License and Open Source Release

Beyond just technical specifications, an important factor that sets Stable Diffusion XL apart is its open licensing and availability. In contrast to many other generative AI models limited to commercial platforms and closed datasets, SDXL 1.0 has been released under an open source and commercial license – expanding the potential for creative applications of the technology. Stability AI’s decisions around licensing and distribution reveal an inclusive ethos that aims to fuel experimentation, education and progress through transparency and accessibility.
Commercial use license
According to Stability AI, Stable Diffusion XL 1.0 has been released under a commercial license, meaning companies can legally use the model for commercial products and services. This differs from some other generative AI models limited to non-commercial research and educational purposes.
Stability AI’s decision to grant commercial rights to SDXL 1.0 from the outset aims to accelerate positive real-world applications of the technology. By allowing businesses and organizations – in addition to individual researchers and artists – to build on top of SDXL, Stability AI hopes to foster an “ecosystem of innovation” that drives progress.
The commercial license also helps ensure that SDXL proliferation will be governed by market forces and user needs – as opposed to being restricted mainly to large tech firms. Many welcome this more open, community-driven approach to generative AI development compared to closed, top-down models.
Overall, Stability AI’s decision to make SDXL 1.0 immediately available for legal commercial use signals its desire to maximize SDXL’s positive societal impact through wide distribution and experimentation. It exhibits Stability AI’s ethos of transparency and openness as a force for good in the generative AI field.- Model weights released for local generation
Community fine-tuning and custom model development
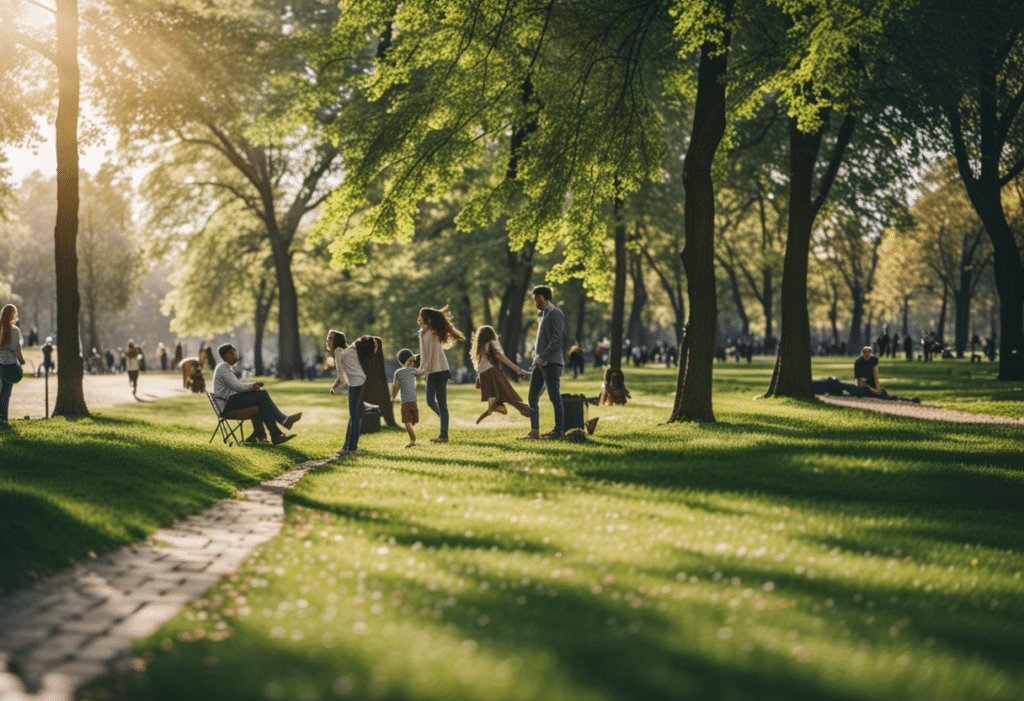
In addition to releasing the SDXL model weights under a commercial license, Stability AI also made them openly available for non-commercial use – allowing hobbyists, researchers and the general public to download and experiment with SDXL locally.
This open source release empowers the AI art community to fine-tune SDXL into customized variants specialized for specific purposes, much like previous Stable Diffusion models. We can likely expect a profusion of niche and aesthetically focused SDXL variants to emerge from the creative AI community, just as specialized SD 1.5 LAIONs proliferated after its release.
Community-driven custom model development leverages the “wisdom of crowds” to expand the uses of generative AI beyond what any single organization could achieve. By distributing SDXL’s baseline capabilities to a global network of diverse thinkers, Stability AI hopes to catalyze wholly new directions and applications for the technology.
Overall, Stability AI’s decision to publicly share the SDXL model weights exemplifies its commitment to openness, transparency and – most importantly – inclusivity in generative AI development. By openly licensing SDXL and empowering the creative AI community to build customized versions, Stability AI aims to foster a more collaborative advancement of the field for the benefit of all.
Image Quality and Capabilities
Beyond technical specifications, the ultimate test for any generative AI model is the quality, diversity and realism of the images it can produce. Stable Diffusion XL excels in all of these areas, delivering a new level of photographic verisimilitude and creative versatility. Examples of SDXL imagery demonstrate its advances in photorealistic rendering, legibility of textual elements, complex scene compositions and high-fidelity depiction of intricate visual phenomena. These capabilities point to fundamental advances in SDXL’s “visual intelligence” – suggesting that generative AI still has far to go before reaching human-level creativity.
Excels at photorealistic images

Many sample images generated by Stable Diffusion XL demonstrate its exceptional capability for producing photorealistic and hyperrealistic scenes, objects and people. Compared to previous SD versions, SDXL images exhibit better color accuracy, more natural lighting and shadows, and finer details – turning textual descriptions into visually plausible depictions of the real world.
Example SDXL images show hyperrealistic depictions of diverse subjects like landscapes, architectural structures, historical scenes, interior settings, vehicles and people. In each case, SDXL accurately renders colors, materials, textures, proportions, spatial relationships and other elements of visual realism with a new level of verisimilitude. Many SDXL images appear nearly indistinguishable from photographs.
The unique combination of SDXL’s higher resolution, stronger photorealistic diffusion, enlarged model size and ensemble of experts architecture comes together to give the model an unprecedented “eye for photographic truth.” When prompted with suitable textual descriptions, SDXL can render visually plausible scenes that trick the human mind into momentarily suspending its disbelief.
However, closer inspection often reveals subtle but telling imperfections that reveal SDXL images as AI-generated – highlighting the gap between even the most advanced generative AI systems and true human-level visual creativity.
High dynamic range and precision text

Some SDXL sample images demonstrate capabilities beyond just photorealism, like high dynamic range between dark and light areas of an image as well as precise generation of textual elements.
Several SDXL images showcase its ability to render scenes with a wide tonal range, from very dark shadows to brightly lit highlights. Complex lighting effects like reflections, light shafts and glow produce a more multidimensional, photographic feel.
At the same time, some SDXL images feature precise renderings of text within the scene in the form of logos, signs, labels and other elements. The generated text exhibits sharp character definitions and high consistency between different instances.
These capabilities point to relevant advances in SDXL’s “vision system.” Its ability to accurately render high dynamic range illumination schemes likely reflects an enhanced ability to model 3D spatial relationships and interpret tone and gradation – key skills for photorealistic depiction. In turn, SDXL’s precision text generation likely emerges from its improved capacity for semantic parsing and textual legibility.
Taken together, SDXL’s human-level capabilities in high dynamic range imaging and textual precision – in addition to its photorealistic synthesis abilities – highlight the rapid progress of generative AI technology. However, SDXL remains firmly in the realm of imitation rather than true creativity -unable to conjure wholly original visual worlds like human artists.
Example images to illustrate different capabilities
Every image in this article has been created using Stable Diffusion XL. But lets look at some more examples to narrow in on the different capabilities that make SDXL so fascinating.

Photorealistic landscape: SDXL can render a scenic outdoor setting with accurate colors, lighting, textures and dimensions that appears nearly photographic.

Complex composition: Generate an image with multiple subjects or objects arranged in a creative composition to demonstrate SDXL’s enhanced ability to manage visual complexity.

Hyperrealistic portrait: Produce a high-fidelity, emotionally evocative face to highlight SDXL’s person-generation advances and extreme photorealism.

Legible logo: Create an image featuring a company logo, sign or other text element with sharp visual clarity and precise character reproduction to illustrate SDXL’s text generation skills.

High dynamic range: Generate a scene with rich tonal range from very dark to very light areas showcasing SDXL’s improved capability to model luminosity and spatial relationships.

Intricate details: Produce an image containing elements with tiny, nuanced features that previous diffusion models struggled with, e.g small objects, textures, facial details.
Ethical Concerns and Mitigation
As with all generative AI systems, Stable Diffusion XL’s capabilities raise potential ethical issues and risks that must be responsibly managed. Any technology with the power to generate vast amounts of synthetic media must contend with the potential for misuse, manipulation and harm. While SDXL does not inherently pose more risks than previous diffusion models, its improvements in image quality and realism increase the onus on Stability AI and users to mitigate adverse outcomes.
With great power comes great responsibility – and the need for thoughtful governance that balances access, innovation and safety.
Potential abuse, deepfakes and other harms
Like all generative AI image models, Stable Diffusion XL could enable the creation of non-consensual or misleading imagery that facilitates harassment, disinformation and other harms. This includes the potential generation of deepfakes, propaganda, fake news, graphic content and images violating intellectual property rights or artist wishes.
As SDXL can produce more realistic fakes than previous versions, there are legitimate concerns that bad actors could exploit its capabilities to facilitate illegal or unethical activities. SDXL’s accessibility and widespread availability also raise the risk of scale effects where even rare abusive uses may become common given a large enough user base.
However, researchers argue that generative AI models are ultimately neutral tools – neither inherently “good” nor “bad.” Their societal impact depends mainly on how they are governed, monitored and regulated – as well as on user ethics and competence. Banning open source generative AI research is not a feasible solution; the most ethical path forward involves proactive risk mitigation strategies and governance frameworks that respect human rights and the public interest.
Stability AI’s mitigation efforts
In response to potential harmful uses of Stable Diffusion XL, Stability AI has taken some initial steps to mitigate risks and ensure safe usage of the model. These include:
- Filtering SDXL’s training data to remove “unsafe” images
- Providing warnings and recommendations against generating illegal/harmful content
- Blocking as many known sensitive/offensive text prompts as feasible
- Collaborating with Spawning.ai to respect artists’ opt-out requests
- Partnering with AI Foundation to develop safe use guidelines
However, Stability AI acknowledges that full prevention of abusive/harmful SDXL uses is impossible given the model’s open source release and accessibility. Instead, the company aims to create a “healthy ecosystem” around the technology through partnerships, community feedback and ongoing mitigation efforts.
Overall, Stability AI’s early risk governance attempts with SDXL illustrate the magnitude of the challenge ahead for ethically managing open source generative AI technologies. While no solutions are perfect, transparency, community engagement and constant improvement are key to responsible diffusion model stewardship.
Using Stable Diffusion XL

Now that you understand Stable Diffusion XL’s capabilities and limitations, the next logical question is: how do I actually use this technology to generate images? There are several ways to access SDXL 1.0 – both through mainstream AI services and by running your own local instance. In this section, we’ll cover the basics of installing and prompting SDXL through the most popular methods, from Stability AI’s own applications to Open Source tools. With the right techniques and settings, you’ll be on your way to generating stunning visual creations with Stable Diffusion XL.
Use Magai’s Image Editor
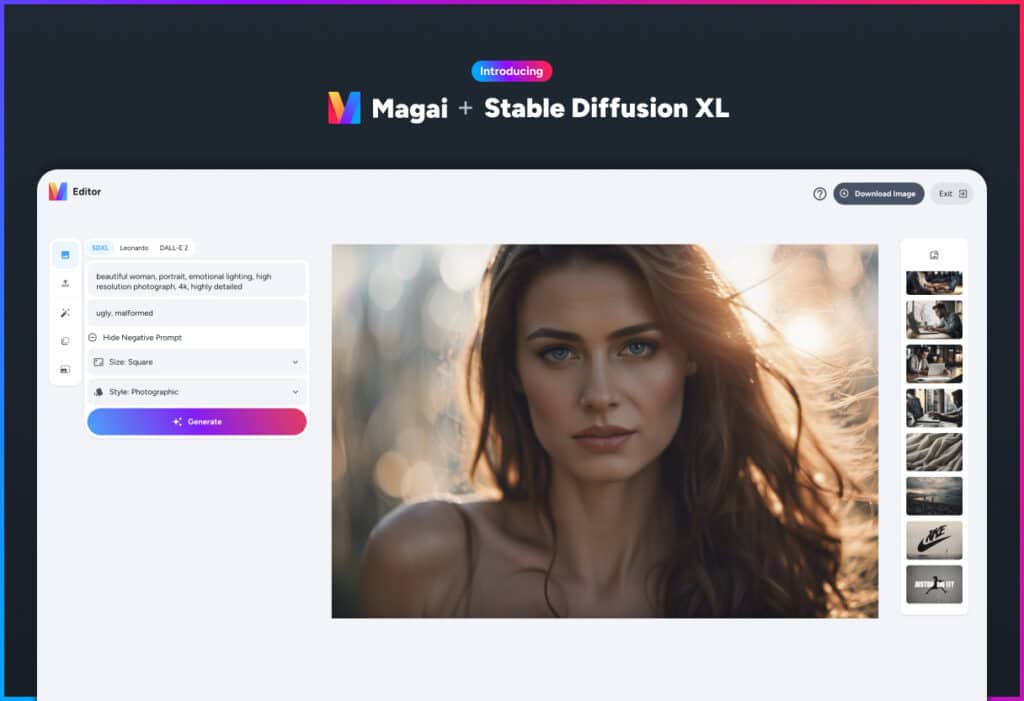
Magai gives you an intuitive, streamlined way to generate Stable Diffusion XL images straight from our application.
To get started:
1) Open Magai’s Image Editor.
2) Select “SDXL” as the image generator (active by default)
3) Enter your text prompt describing the desired image in the “Prompt” field.
4) Optionally enter a “Negative Prompt” to exclude unwanted concepts.
5) Choose from 3 preset resolutions:
- Square (1024×1024)
- Wide (1216×832)
- Tal (832×1216)
6) Select a Style from the dropdown to fine-tune the result.
7) Click “Generate” to create your Stable Diffusion XL image.
Magai’s Image Editor for SDXL offers:
- Simple, streamlined input fields
- Useful preset sizes optimized for SDXL
- Built-in style options for quick modifications
- Integrated AI enhancements within Magai’s suite of AI tools
Overall, Magai’s approach aims to make Stable Diffusion XL easy and intuitive to use, while still providing enough controls to unlock its full creative potential. Our guided yet flexible interface provides an ideal balance between accessibility and power – helping spark new ideas and visual wonders with just a few clicks.
Get creative with SDXL & Magai
Get access to all the most powerful AI models inside one beautiful interface.




Download and run locally
For the most control and customizability, you can download the Stable Diffusion XL 1.0 model weights and run your own local instance. This requires a powerful GPU and familiarity with command line interfaces.
To run SDXL locally, you’ll need to:
1) Download the base SDXL model and optional LAION refiner model from Stability AI’s GitHub.
2) Extract the model weights and place them in the correct folders.
3) Install and run an open source diffusion model runner like Automatic1111 that supports SDXL.
4) Inside the runner, select the SDXL base and refiner models where appropriate.
5) Optimize settings like resolution, denoise strength, CFG steps, and sampler.
6) Input your chosen text prompt and generate an image.
7) Optionally use the refiner model to improve the initial output.
With a local setup, you have full control over settings, Sampling algorithms, and model fine-tuning – allowing for the deepest creative exploration of Stable Diffusion XL. However, it requires more technical know-how and computational resources than alternative options.
Use stability.ai applications
For a simplified experience, you can access Stable Diffusion XL via Stability AI’s official applications like ClipDrop and DreamStudio.
To generate SDXL images through these services, you’ll generally:
1) Create a free Stability AI account.
2) Select Stable Diffusion XL as the model within the application.
3) Input a text prompt describing the desired image.
4) Adjust settings as desired like resample count, denoise strength, and resolution.
5) Click “Generate” to create the image.
6) Optionally refine the output using the SDXL refiner model.
Stability AI applications offer a user-friendly interface for experimenting with SDXL, automating technical setup and providing collab spaces. However, functionality is sometimes limited versus local setups and you must rely on Stability AI’s infrastructure.
Overall, Stability AI’s applications represent a good middle ground between a fully open local setup and a closed commercial platform. They allow accessible SDXL use while maintaining much of the creative freedom of an open source model – at the cost of some degree of control and privacy.
Looking Ahead

While Stable Diffusion XL 1.0 represents an impressive advance in AI image generation, it is only the beginning of a longer journey toward more capable and creative generative AI systems. As researchers, artists and developers explore the possibilities unlocked by SDXL, fundamental questions about the technology’s applications, limitations, and governance will continue to demand thoughtful answers. By charting a responsible course that harnesses SDXL’s potential for good while guarding against risks, we can maximize the model’s contributions to science, culture and human flourishing. The road ahead remains long – but our first steps will determine the overall direction of the path.
Potential for further improvements
As Stability AI continues to refine its generative AI technology, future versions of Stable Diffusion will likely show performance gains beyond what SDXL 1.0 currently offers. Possible enhancements include:
- Even higher resolution image generation (e.g. 2048×2048 pixels)
- Greater creative versatility across different art styles and concepts
- More coherent and grounded image synthesis from text prompts
- Enhanced capabilities for animation, 3D modeling and other modalities
However, fundamental barriers still exist that limit diffusion models – related to issues like intrinsic biases, lack of commonsense knowledge and inability to originate truly novel concepts. Overcoming these limits will require whole new approaches that go beyond scaling up existing architectures.
Overall, while Stable Diffusion XL represents an encouraging step forward, the gulf between even the most advanced generative AI systems and human-level visual creativity remains vast. Bridging that gap will demand transformative advances – not just incremental progress through scaling existing techniques. True creative AI remains on a distant horizon.
Outlook for community model development
Just as hobbyists, researchers and artists fine-tuned previous Stable Diffusion models into specialized variants, Stability AI expects a wave of customized SDXL versions to emerge from the creative AI community.
With higher resolution, faster model training and better capabilities out of the box, SDXL’s open source release is poised to supercharge community-driven generative AI development. We are likely to see:
- Finer-grained custom models focused on narrow aesthetic goals or art styles
- Novel multi-model ensembles combining SDXL with other techniques
- Advances in stabilizing, augmenting and curating SDXL’s output
- Unique applications of SDXL in fields like art, design, education and beyond
Overall, widespread access to the SDXL model weights represents an infusion of creative potential into global communities of thinkers, tinkerers and dreamers. Their experimentation and hacks will push the boundaries of what generative AI technology can accomplish – advancing science and culture in unforeseen ways.
Stability AI’s decision to openly share SDXL 1.0 exemplifies the benefits of grassroots, collaborative innovation over jealously guarded intellectual property. By empowering the creative AI “cognoscenti,” the entire field stands to benefit from their restless experimentation and discovery.
Questions around content monitoring and moderation
As Stability AI and SDXL users continue efforts to mitigate abusive or harmful uses of the model, difficult questions will inevitably arise around user surveillance, content policing and free expression.
Issues to navigate include:
- How can unsafe content be detected without compromising users’ privacy?
- What degree of human review is needed to balance accessibility and safety?
- How should edge cases be evaluated to avoid inconsistent or biased decisions?
- How can content policies evolve in response to community feedback and new risks?
Finding workable solutions will require a multi-pronged approach, including:
- Transparent content guidelines that balance protecting the vulnerable with respecting free expression
- Technological means of automatically detecting potential harms while minimizing false positives
- Processes for individuals to appeal content decisions in an unbiased manner
- Open dialogues between stakeholders to constantly reevaluate policies and practices
Overall, responsibly managing open source generative AI like Stable Diffusion will require novel governance systems that combine the best of human judgement, community input and AI assistance. There are no simple technological “fixes” – only an ongoing, good-faith effort to balance competing values through transparency, adaptability and humanity.
The road ahead remains long and uncertain. But with wisdom, compassion and a willingness to listen to diverse perspectives, we can chart a sensible course forward – one that fulfills generative AI’s promise of unleashing unprecedented human creativity while avoiding its pitfalls.



